Credit Risk Assessment Models in Financial Technology: A Review
Modelos para la evaluación de riego crediticio en el ámbito de la tecnología financiera: una revisión
 PDF
PDF
Received: March 24, 2023
Accepted: October 30, 2023
Available: December 20, 2023
F. E. Tadeo Espinoza and M. A. Coral Ygnacio, “Credit Risk Assessment Models in Financial TecnoLógicas, vol. 26, nro. 58, eXXX, 2023. https://doi.org/10.22430/22565337.2679
Highlights
Highlights
Abstract
This review analyzes a selection of scientific articles on the implementation of Credit Risk Assessment (CRA) systems to identify existing solutions, the most accurate ones, and limitations and problems in their development. The PRISMA statement was adopted as follows: the research questions were formulated, the inclusion criteria were defined, the keywords were selected, and the search string was designed. Finally, several descriptive statistics of the selected articles were calculated. Thirty-one solutions were identified in the selected studies; they include methods, models, and algorithms. Some of the most widely used models are based on Artificial Intelligence (AI) techniques, especially Neural Networks and Random Forest. It was concluded that Neural Networks are the most efficient solutions, with average accuracies above 90 %, but their development can have limitations. These solutions should be implemented considering the context in which they will be employed.
Keywords: credit assessment, credit risk, technology solutions, machine learning, algorithms
Resumen
Esta revisión analiza una selección de artículos científicos sobre la implantación de sistemas de evaluación del riesgo de crédito para identificar las soluciones existentes, las más acertadas y las limitaciones y problemas en su desarrollo. Se adoptó la declaración PRISMA del siguiente modo: se formularon las preguntas de investigación, se definieron los criterios de inclusión, se seleccionaron las palabras clave y se diseñó la cadena de búsqueda. Por último, se calcularon varios estadísticos descriptivos de los artículos seleccionados. En los estudios seleccionados se identificaron 31 soluciones, entre métodos, modelos y algoritmos. Algunos de los modelos más utilizados se basan en técnicas de Inteligencia Artificial (IA), especialmente Redes Neuronales y Bosques Aleatorios. Se concluyó que las Redes Neuronales son las soluciones más eficientes, con precisiones medias superiores al 90 %, pero su desarrollo puede tener limitaciones. Estas soluciones deben implementarse teniendo en cuenta el contexto en el que se van a emplear.
Palabras clave: evaluación crediticia, riesgo de crédito, soluciones tecnológicas, aprendizaje automático, algoritmos
1. INTRODUCTION
Credit risk is defined as the classification or evaluation that is assigned to someone after having applied for a loan from a bank. The main task of Credit Risk Assessment (CAR) systems is to solve the problem of classifying customers based on their behavior or credit history [
This is a brief description of the problem in CRA. Hence, new and affordable technologies should be adopted in CRA to support the loan granting decisions of banking institutions [
CRA can use technology-based methods, models, and algorithms to make predictions and select borrowers [
Among the statistical models most commonly used for data treatment in CRA systems, the most popular is the Synthetic Minority Over-sampling Technique Evaluation (SMOTE) [
In CRA systems, AI techniques have been especially used to process and classify data-substituting human analysis to improve the accuracy and speed of the assessment. Based on predictions, these systems classify the risk level of a loan by evaluating different variables: economic, social, demographic, financial factors, etc. [
CRA systems appeared at the beginning of the 2000s, with the development of new technologies and financial institutions’ need for information systems that could conduct CRA. The first CRA systems implemented algorithms and statistical techniques based on financial models to determine potential debtors [
CRA systems also involve the use of different financial models, which should be compared and validated with suitable theoretical foundations to provide reliable solutions. In addition, these systems include statistical models to treat vast amounts of data, which is necessary to continuously improve them [
In these systems, the literature recommends the implementation of ML techniques, especially algorithms based on Random Forest, thanks to their accuracy considering several factors. It also recommends AI techniques. Among them, the most popular are solutions based on Neural Networks, which combine statistical algorithms and algorithmic processes. The literature also suggests to take into consideration the hardware that is used for CRA, which should be adequate to run the algorithms [
CRA systems need models that determine the variables to be assessed. However, only a few studies analyzed in this literature review describe the logic behind their solutions for CRA. In addition, there is little information on the limitations of CRA systems.
This Systematic Literature Review (SLR) proposes four research questions, which will be detailed later. In particular, this SLR aims to determine what methods, models, and algorithms have been employed in CRA systems; their individual efficiency; the logic behind their assessment models; and their limitations.
This paper describes and analyzes the most efficient solutions used in CRA systems, as well as their limitations and problems.
This SLR followed the PRISMA statement, which offers guidelines to orderly and systematically review published documents about a research topic [
As a result, this SLR found 41 common solutions in CRA systems. Ten of them are techniques based on financial models. This review also determined three limitations or problems that could arise when CRA systems are implemented—one of them is particularly significant and should be considered after the implementation process.
This paper is structured as follows. Section 1 introduces the study and presents the state of the art. Section 2 details the methodology of this SLR and reports the results of the statistical analysis. Section 3 provides answers to the research questions. Finally, Section 4 draws the conclusions of this work.
2. METHODOLOGY
This SLR implemented the PRISMA statement to investigate the available knowledge and studies about the topic addressed here. This statement provides researchers with a framework to adequately carry out SLRs that are accepted by the entire scientific community. It also details the necessary steps for an SLR, including establishing goals, eligibility criteria, results, and conclusions [
In addition, the research objectives of this SLR were clearly established in order to cover and obtain all the necessary information. Table 1 details the four research objectives and four research questions in this SLR based on the PICO (Problem, Intervention, Comparison, and Outcome) model provided by the PRISMA statement. The PICO model is used to formulate research questions [
| Research objectives | Research questions | Approach |
| To determine the methods, models, and algorithms employed in the implementation of CRA systems. | What methods, models, and algorithms are employed in CRA systems? | Quantitative |
| To determine the most efficient methods, models, and algorithms employed in the implementation of CRA systems. | What are the most efficient methods, models, and algorithms in CRA systems? | Qualitative |
| To identify the credit risk models used by banking institutions. | What credit risk models are used by banking institutions? | Qualitative |
| To determine the limitations or problems that may arise in the implementation of CRA systems. | What problems or limitations may arise in the implementation of CRA systems? | Qualitative |
Subsequently, a search string was defined considering three groups of terms that were identified. The first group contained terms related to the implementation of CRA systems, i.e., methods, models, algorithms, and technologies. The second group included terms related to the topic of this review, i.e., credit risk or credit risk assessment. The last group referred to solutions: system, implementation, and software. Considering these three groups of terms, the following search string was formulated: (methods OR models OR algorithms OR technologies) AND (“credit risk” OR “credit risk assessment”) AND (system OR implementation OR software).
In addition, six inclusion criteria were established. First, this SLR included only documents in English as it is the most widely accepted language in this scientific area. Second, to study recent literature, the articles should have been published between 2018 and 2022. Third, to ensure the legitimacy of the material, the articles should be final published versions. Fourth, they should be indexed in research databases. Fifth, the articles should be about Credit Risk Assessment (CRA) systems. Sixth, articles about the implementation of said systems were also included. Table 2 details these criteria.
| Inclusion criteria | Exclusion criteria |
| Articles in English | Articles published before 2018 |
| Articles published between 2018 and 2022 | Articles in languages other than English |
| Final published versions | Literature reviews, meta-analyses, or incomplete papers |
| Articles indexed in research databases | Articles about topics remotely related to the implementation of CRA systems. |
| Articles about CRA systems | Articles without a Digital Object Identifier (DOI) |
| Articles about the implementation of CRA systems |
After the search string and the inclusion and exclusion criteria were defined, the search was conducted in three databases: Scopus, IEEExplore, and ResearchGate. These three databases were selected because we had access to the articles indexed in them. The search was performed on September 13, 2022, and only articles indexed in those databases were selected.
A preliminary search found 2,285 articles in these three databases. Among them, 88 were excluded because they were duplicates. Then, 1,860 records were excluded as they did not meet the pre-established inclusion criteria. At that point, there were 337 articles: 82 in Scopus, 117 in IEEExplore, and 38 in ResearchGate. Afterward, the titles and abstracts of the documents were analyzed to determine if they latter were about topics closely related to the implementation of CRA systems. After this process, there were 104 articles: 71 in Scopus, 17 in IEEExplore, and 16 in ResearchGate. Subsequently, the full text of these articles was examined to evaluate their connection to the research topic addressed of this study. Thus, other 35 records were excluded, for 69 articles in the final sample. This process is described in detail in Figure 1.
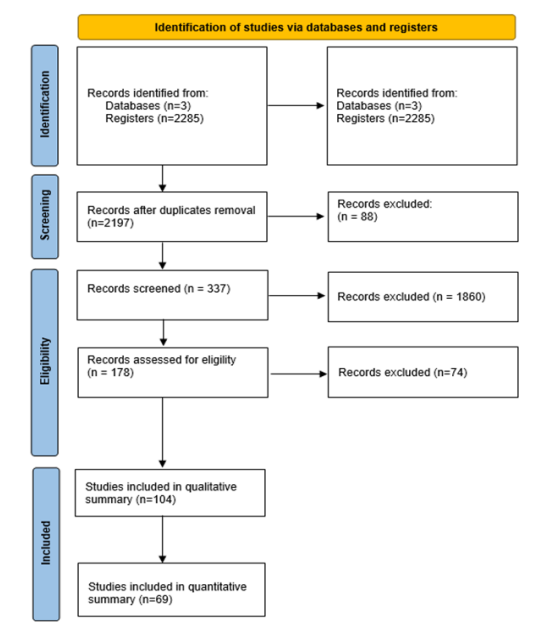
In this methodology, due to the criteria established and the limited access to articles behind paywalls, the results could present some bias. Because of funding reasons, only articles we had access to were reviewed. In addition, time and language limitations influenced the course of this study. The list of all the articles that were selected for this review was used to generate a series of figures to illustrate the characteristics of these documents.
Figure 2 details the number of documents published every year in the selected period. The year 2021 presented the highest number of publications (26), followed by 2022 (15). This figure shows the publication trend in this field during that period.
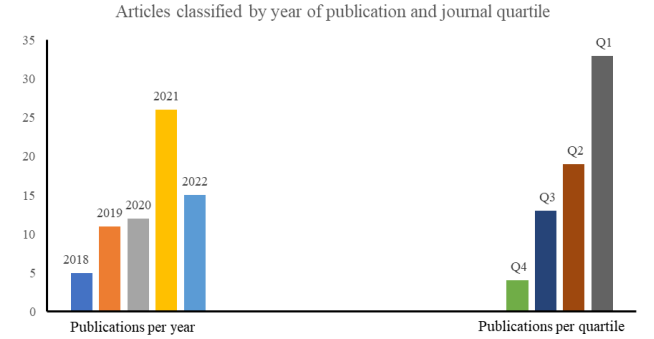
It also includes the distribution of those articles into the quartiles of the journals where they were published. The website Scimago was used to classify the journals into quartiles (from Q1 to Q4). The results show that 33 of the articles were published in Q1 journals; 19, in Q2; 13, in Q3; and 4, in Q4. This chart provides information about the quality and impact of the sources where the articles were published.
In Figure 3, the articles are classified based on the nationality of their main author. Most of them are from China (36), followed by India (5), the US (4), and the UK (4).
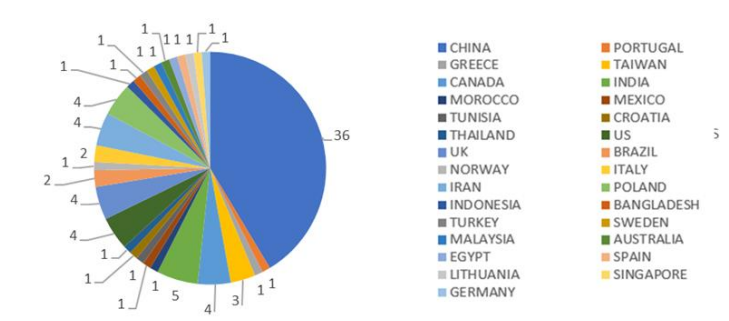
Table 3 lists the top 15 articles in number of citations, showing the most influential papers in this research field.
| Reference | Title | Citations |
| [ |
Forecasting SMEs’ credit risk in supply chain finance with an enhanced hybrid ensemble machine learning approach | 111 |
| [ |
Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring | 95 |
| [ |
Predicting mortgage default using convolutional neural networks | 67 |
| [ |
Enterprise credit risk evaluation based on neural network algorithm | 48 |
| [ |
A dynamic credit risk assessment model with data mining techniques: evidence from Iranian banks | 43 |
| [ |
Loan evaluation in P2P lending based on Random Forest optimized by genetic algorithm with profit score | 41 |
| [ |
SecureBoost: A Lossless Federated Learning Framework | 40 |
| [ |
Credit risk modeling using Bayesian network with a latent variable | 35 |
| [ |
Multi-view ensemble learning based on distance-to-model and adaptive clustering for imbalanced credit risk assessment in P2P lending | 33 |
| [ |
Big data analytics on enterprise credit risk evaluation of e-Business platform | 32 |
| [ |
A novel classifier ensemble approach for financial distress prediction | 31 |
| [ |
Automatic feature weighting for improving financial Decision Support Systems | 22 |
| [ |
Type-1 OWA Unbalanced Fuzzy Linguistic Aggregation Methodology: Application to Eurobonds Credit Risk Evaluation | 22 |
| [ |
An economic order quantity model under two-level partial trade credit for time varying deteriorating items | 21 |
| [ |
Utilizing historical data for corporate credit rating assessment | 19 |
| Total | 660 |
In turn, Figure 4 shows the countries where the articles included in this SLR were published. Again, most of them were published in China (33), followed by India (5).
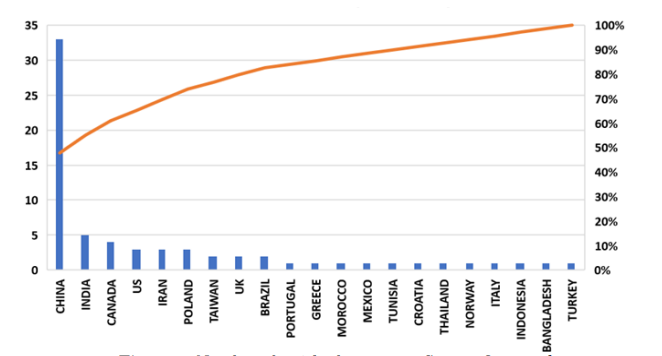
Table 4 details all the keywords retrieved from the selected documents. They were grouped into three themes: technologies, supply chain, and financial processes. The first theme includes 32 keywords related to technologies that are employed to implement CRA systems. The second one features three terms associated with the supply chain. The third theme has 22 keywords related to financial processes in CRA.
| Theme | Keywords |
| Technologies | Machine learning, fuzzy random forest, Genetic algorithm, logistic regression, python web framework2, Predictive intelligence, Deep multiple kernel classifier, Deep learning, Optimal model, Data mining, EM algorithm, Deep neural network, Mixture model, Z-Score Model, Internet of Things, RS-MultiBoosting, improved neural network, Random Forest, explainable algorithms, Deep forest, fuzzy clustering, Artificial Neural Networks, random forest, support vector machine;, Firefly algorithm, SAW Method, Oriented Fuzzy Number, artificial intelligence, Machine learning algorithms, Prediction algorithms, XGBoost, CatBoost algorithm, Data mining, EM algorithm, Deep neural network, Mixture model, Z-Score Model, Internet of Things, RS-MultiBoosting, improved neural network, Random Forest, explainable algorithms. |
| Supply chain management | Supply chain management, supply chain finance, supply chain financing. |
| Financial processes | Credit risk scoring, Credit risk, Credit scoring, Bankruptcy prediction, Banknote authentication, Credit scoring, Optimal model, e-Business, Credit risk assessment, Intelligent Manufacturing, Risk analysis, P2P lending, Peer-to-peer lending, Mortgage default model, financial credit evaluation assessment, Internet finance, Federated Learning, systemic risk, soft information, Credit scoring model, feature selection, Feature selection. |
Following the PRISMA statement, the next step was to extract key information from the selected documents. This included methods, results obtained, and any other variables that might have been relevant for the objectives of this review. The data was extracted systematically and following a pre-established protocol.
Subsequently, the results of this data extraction were summarized to identify patterns and trends and draw conclusions about the reviewed literature. This enabled us to address the research objectives and answer the research questions.
Simultaneously, the quality of the studies was assessed. The PRISMA statement encourages researchers to conduct a critical assessment of the methodological quality of the selected studies. This includes factors such as study design, sample size, validity of the results, and presence of possible bias. The quality of the selected studies was taken into account in the interpretation of the results. When the selected studies presented comparable and sufficiently homogenous results, a meta-analysis was conducted to combine the data and obtain global estimations of the effects. This contributed to a more accurate assessment of the available information. Finally, the heterogeneity and bias in the included studies were continuously evaluated. Thanks to this continuous evaluation, it was possible to identify possible sources of heterogeneity and bias as the review progressed, which contributed to a more accurate interpretation of the results.
3. RESULTS AND DISCUSSION
3.1 Research question 1: What solutions are used in CRA systems?
In different studies, diverse computational solutions have been implemented in CRA systems. These solutions can be classified into three types: methods, models, and algorithms. Authors in this field adopt a particular solution in accordance with the topic they are investigating or their purpose. Table 5 details the solutions identified in the reviewed studies (31 references).
| Reference | Solution | Description |
| [ |
SMOTE-PSO-LSSVM | This method consists in the application of a synthetic minority oversampling technique (SMOTE) and the least square support vector machine (LSSVM) algorithm optimized by particle swarm optimization (PSO). |
| [ |
CNN Model | This multi-layer hierarchical model performs several transformations using a set of convolutional kernels. The convolution procedure helps to extract valuable characteristics from data points that are spatially connected. |
| [ |
Deep Multiple Kernel Classifier | This method is an optimized version of the Deep Learning structure. It uses multiple processing kernels instead of just one to increase richness in the representation of the features. |
| [ |
RB Genetic Algorithm | This algorithm combines the adaptive random balance (RB) method and the XGBoost algorithm to construct a credit risk assessment model. |
| [ |
Genetic Algorithm | This paper describes an adaptive sequential-filtering learning system for credit risk modeling using genetic algorithms for preselected patterns. |
| [ |
SMOTE algorithm | The SMOTE algorithm is an oversampling technique in which synthetic samples are generated for the minority class. This algorithm can solve the overfitting problem posed by random oversampling. |
| [ |
Dynamic mutation Particle Swarm Optimization (PSO) algorithm | The algorithm in this article was designed to avoid the problem of particles falling into local optima in the optimization process. It is used to optimize the SVM parameters and the integration of AdaBoost as a weak classifier to build an integrated model with good performance in many aspects. |
| [ |
Convolutional Neural Network (CNN) method | In this method, a series of networks are created inspired by the way a human brain works. These networks can learn on different levels of abstraction. |
| [ |
Bayesian Network (BN) with a latent variable | In this model, while the BN structure models the probabilistic relationships between the factors that lead to credit default payment, the latent variable can be used to represent different classes of probability distributions. |
| [ |
Deep Neural Networks | The main purpose of this method is to receive a set of inputs, make progressively more complex calculations on them, and provide an output to solve real-life problems, such as classification. It is limited to feeding the neural networks. |
| [ |
Random forest algorithm | The weighted random forest algorithm is used to classify the financial credit risk data, construct the evaluation index system, and use the analytic hierarchy process to evaluate the financial credit risk level. |
| [ |
RS-MultiBoosting | This approach consists of two classical ensemble ML approaches, i.e., random subspace (RS) and MultiBoosting, to improve the forecasting performance of SMEs’ credit risk. The forecasting result shows that RS-MultiBoosting has good performance in dealing with a small sample size. |
| [ |
AHP-LSTM | This model consists of the analytic hierarchy process (AHP) and the long short-term memory (LSTM) model. Firstly, the characteristic information is extracted, and the financial credit risk assessment index system structure is established. The data are input into the AHP-LSTM neural network, and the index data are fused with the AHP so as to obtain the risk level and serve as the expected output of the LSTM neural network. |
| [ |
Bagging algorithm for Random Forest | The random forest algorithm is an example of a bagging ensemble. It consists in training a series of decision trees so that later they (1) do a majority voting in classifications or (2) obtain the mean in regression problems. |
| [ |
Multi-layer gradient boosting decision tree (GBDT) | In this model, gradient boosting decision trees are used to optimize the prediction results by means of ML processes. |
| [ |
Distance-to-model and adaptive clustering-based multi-view ensemble classification method | In this method, multi-view ensemble learning and a method based on adaptive clustering are used to produce a set of different ensembles composed of gradient boosting decision trees. |
| [ |
Back Propagation Neural Network (BPNN) | In this article, BPNN methods are applied to design a default prediction model for online loans. It was demonstrated that said model (based on BPNN) presents high applicability and prediction accuracy compared to other models. |
| [ |
ReG-Rules | This study describes the general framework of a rule-based ensemble classification system which consists of 5 stages with several operations: (1) Diversity Generation, (2) Base Classifiers Inductions, (3) Models Selection, (4) Rule Merging, and (5) Combination and Prediction. |
| [ |
Multi-grained augmented gradient boosting decision tree (mg-GBDT) | A multi-grained scanning is introduced for feature augmentation, which enriches the input feature of GBDT; the GBDT-based step-wisely optimization mechanism ensures low-deviation of credit scoring; besides, the proposed method inherits the good interpretability of tree-based structure, which provides intuitive reference results for policy-makers. |
| [ |
Support vector machines | This approach includes three components: (1) a novel noise filtering scheme that avoids noisy examples based on fuzzy clustering; (2) the principal component analysis algorithm, which was used to eliminate noise in attributes and classes to produce an optimal clean dataset; and (3) the classifiers of the support vector machine, based on the improved particle swarm optimization algorithm. |
| [ |
Machine Learning | These two papers compare several ML-based models that can be employed in the development of a credit risk assessment system. |
| [ |
Parallel Artificial Neural Networks (PANNs) | The proposed Parallel ANNs model consists of three stages; the first stage is to create the neural network classifiers; the second stage is to integrate multiple classifiers into an ensemble output; the third stage is to perform the learning process of the PANNs model. |
| [ |
Firefly algorithm | This article proposes an improvement to the firefly algorithm to solve optimization problems and feature selection. |
| [ |
Imperialist competitive algorithm with modified fuzzy min–max classifier (ICA-MFMCN) | This algorithm was designed to identify an optimal subset of features and increased through accuracy classification and scalability through assessment of credit risk. |
| [ |
Fuzzy Neural Network | In this study, a credit risk assessment system called SC-IR2FNN is developed based on fuzzy neural networks. |
| [ |
Adaptive network-based fuzzy inference system (ANFIS) | This adaptive network-based system was implemented to design an adaptive credit risk assessment model that removes human judgement completely. |
| [ |
Support vector machine (SVM) | The concept of SVM is to find optimal hyper plane with maximum margin to linearly separate the data set into two classes. |
| [ |
CatBoost algorithm | Swindle implements CatBoost algorithm is used for predicting loan defaults along with a document verification module using Tesseract and Camelot and also a personalized loan module, thereby mitigating the risk of the financial institutes in issuing loans to defaulters and unauthorized customers. |
3.2 Research question 2: What are the most efficient solutions to implement a CRA system?
The efficiency of the solutions found in the selected articles was evaluated based on the accuracy percentage of the systems developed and described by the authors. There are three efficiency levels: inefficient, efficient, and very efficient. Table 6 details the solutions and their efficiency levels.
| Reference | Solution | Efficiency level | Advantages/Disadvantages | Conditions |
| [ |
SMOTE-PSO-LSSVM | Very efficient | It improves accuracy as it addresses data imbalance, but it can be computationally expensive. | Ideal for imbalanced datasets. |
| [ |
CNN Model | Very efficient | Effective in the extraction of complex data features, but it requires a large volume of data to be trained. | Recommended for large amounts of data. |
| [ |
Deep Multiple Kernel Classifier | Efficient | It can deal with nonlinear features, but it may require adjustments for sensitive hyper-parameters. | Ideal for nonlinear relationships between features. |
| [ |
RB-XGBoost algorithm | Efficient | It strikes a good balance between speed and performance, but it may be susceptible to overfitting. | Suitable for medium-size and big datasets with mixed features. |
| [ |
Genetic Algorithm | Efficient | It can find global solutions, but it may have a higher computational cost. | Useful to find optimal solutions in complex search spaces. |
| [ |
SMOTE algorithm | Very efficient | Its performance improves in minority classes, but it may produce synthetic samples superimposed on existing ones. | Recommended to deal with class imbalances. |
| [ |
Dynamic mutation particle swarm optimization algorithm (AdaBoost-DPSO-SVM) | Very efficient | It combines multiple algorithms to have better accuracy, but it is computationally demanding. | Suitable when the goal is high performance and multiple algorithms can be used. |
| [ |
Convolutional Neural Network (CNN) method | Very efficient | Effective in the extraction of complex data features, but it requires a large volume of data to be trained. | Recommended for large amounts of data. |
| [ |
Bayesian Network (BN) with a latent variable | Very efficient | It can handle uncertainty effectively, but its operation is more complex. | Ideal for modeling uncertainty when probabilistic information is available. |
| [ |
Deep Neural Networks | Efficient | They can learn complex data representations but require large volumes of training data. | Suitable for problems with complex and scattered data. |
| [ |
PNN | Efficient | It can classify patterns fast, but it becomes less efficient as the number of parameters increases. | Useful for quick classifications with a few parameters. |
| [ |
Random forest algorithm | Very efficient | It is effective with noisy data and remotely related features. | Recommended if the data structure or volume are unknown. |
| [ |
RS-MultiBoosting | Efficient | It is efficient in multi-class classification, but its accuracy is low in the face of noisy data. | Useful for multi-class classifications with clean datasets. |
| [42] | AHP-LSTM | Very efficient | It incorporates multi-criteria analysis in the learning process, which involves more complexity. | Adequate when multiple criteria should be considered in decision-making. |
| [ |
Random Forest optimized by genetic algorithm with profit score | Efficient | It offers better optimization, although with more complexity. | Ideal for maximizing classification results. |
| [ |
Bagging algorithm for Random Forest | Very efficient | It can reduce variance and overfitting, but it may not work so well with highly imbalanced data. | Suitable for classification problems with high variance. |
| [ |
Multi-layer gradient boosting decision tree (GBDT) | Efficient | It can deal with different types of features better, although it requires more parameter adjustments. | Ideal when the data to be processed have mixed features. |
| [ |
Distance-to-model and adaptive clustering-based multi-view ensemble (DM–ACME) classification method | Efficient | It can efficiently process multi-view data, but it requires a careful selection of features. | Suitable for multi-view learning. |
| [ |
Back Propagation Neural Network (BPNN) | Very efficient | Suitable for regression and classification problems, but it is less efficient with big datasets. | Useful for limited datasets because it is less efficient as the dataset is larger. |
| [ |
Convolutional Neural Network (CNN) method | Very efficient | Suitable for rule-based problems, but it might be less accurate than complex models. | Recommended for large amounts of data. |
| [ |
ReG-Rules | Very efficient | Suitable for rule-based problems, but it might be less accurate than complex models. | Ideal for interpretability and clear rules. |
| [ |
Multi-grained augmented gradient boosting decision tree (mg-GBDT) | Inefficient | It works well in problems with multiple granularity levels, but it is slow compared to other algorithms. | Useful to model data granularity in test models. |
| [ |
EN-AdaPSVM model | Very efficient | It combines multiple algorithms to improve its performance, but it requires more computational power. | Suitable when the goal is high performance and multiple algorithms can be used. |
| [ |
Machine Learning | Efficient | It can be more flexible depending on the algorithm employed, although it requires more adjustments. | Ideal for a final classification of different kinds of data. |
| [[ |
Parallel Artificial Neural Networks (PANNs) | Efficient | They exploit parallel computing for efficient data processing, but that increases the complexity of the algorithm. | Useful to improve the processing speed for specific data volumes. |
| [ |
Firefly algorithm | Efficient | It can be used for a global optimization of the implementation, but it may require parameter adjustments. | Useful to find optimal solutions in complex search spaces. |
| [ |
Imperialist competitive algorithm with modified fuzzy min–max classifier (ICA-MFMCN) | Efficient | It can deal with uncertainty and classifications with high numbers of parameters. | Recommended to deal with uncertainty in credit assessment. |
| [ |
Fuzzy Neural Network | Efficient | It is suitable for problems with high uncertainty and data that have not been normalized yet. | Useful to model relationships between data to determine common features. |
| [ |
Adaptive network-based fuzzy inference system (ANFIS) | Efficient | It combines fuzzy logic and machine learning to obtain better results, but it may require parameter adjustments. | Adequate to determine relationships between features and when training data are available. |
| [ |
Support vector machine (SVM) | Very efficient | It can efficiently separate linear and nonlinear classes, but it is largely dependent on kernel selection. | Recommended for high-performance classification problems. |
| [ |
Machine Learning | Very efficient | It can be more flexible depending on the algorithm employed, although it requires more adjustments. | Recommended for a general solution with different types of data. |
| [ |
PCA-GA-FS model | Very efficient | It combines feature selection and dimensionality reduction techniques, although it may require parameter adjustments. | Useful to obtain a more compact representation of the data. |
| [ |
CatBoost algorithm | Efficient | It was optimized for sets of categorical data, although it may be sensitive to hyper-parameter selection. | Suitable for datasets with many categorical features. |
3.3 Research question 3: What credit risk models are used by banking institutions?
This review also identified financial models that banking institutions use for CRA. A credit assessment model can assign weights to qualitative and quantitative variables to evaluate customer credit quality [54]. These models enable banking institutions to measure (based on their own variables and specifications) the risk level that represents granting a loan to a borrower. Table 7 details the credit risk models identified in this review.
| Reference | Model | Comment |
| [ |
Comprehensive model for credit scoring | The objective of this model is to support decision-making by collecting data and applying statistics, artificial intelligence, and other techniques. |
| [ |
Economic order quantity model under two-level partial trade credit | This article proposed a two-level credit model for time varying deteriorating items. Due to the granting credit terms, we applied default risk. Moreover, we assume that the supplier/retailer offers the partial trade credit to the retailer/customer. |
| [ |
Optimal backward elimination model and forward regression method | The purpose of this paper is to verify whether there is a relationship between credit risk, main threat to the banks, and the demographic, marital, cultural, and socio-economic characteristics of a sample of 40 credit applicants, by using the optimal backward elimination model and the forward regression method. |
| [ |
Credit evaluation adjustment method | According to the measurement requirement of counterparty credit risk in Basel Accord, counterparty credit risk-weighted asset is the summation of the default risk-weighted asset of counterparty credit risk and the credit valuation adjustment risk-weighted asset. |
| [ |
Additive generalized models | It outlines the implementation via frequentist and Bayesian MCMC methods. We apply them to a large portfolio of credit card accounts, and show how GAMs can be used to improve not only the application, behavioral and macro-economic components of survival models for credit risk data at individual account level, but also the accuracy of predictions. |
| [ |
Logistic regression model | According to the definition of whether the dependent variable borrower defaults in Logistic regression, the borrower is divided into default and non-default. Among them, non-default borrowers are marked as 0, and default borrowers are marked as 1. |
| [ |
Binary spatial regression model | This study applied a binary spatial regression model to measure contagion effects in credit risk arising from bank failures. To derive interconnectedness measures, we use the World Input-Output Trade (WIOT) statistics between economic sectors. |
| [ |
B2B supply chain | Based on the B2B e-commerce platform, it is used for online transactions and transactions between companies and companies. Information, integrating logistics, business flow, information flow, and capital flow for data analysis and processing. |
| [ |
Type-1 OWA Unbalanced Fuzzy Linguistic Aggregation Methodology | The T1OWA operator methodology is used to assess the creditworthiness of European bonds based on real credit risk ratings of individual Eurozone member states modeled as unbalanced fuzzy linguistic labels. |
| [ |
Moral hazard model | Moral hazard is a problem mainly caused by ex-post information asymmetry in a contract especially after signing the contract. This problem arises due to the inability of agents to be able to observe the actions of other agents. |
A total of 10 models were found in the selected documents. They define the necessary variables for CRA and are adapted according to specific requirements. Many of these models include the demographic characteristics of the applicants to improve the accuracy of the assessment.
3.4. Research question 4: What problems or limitations may arise in the implementation of CRA systems?
Finally, in the selected articles, this review found three limitations or problems that may arise in the implementation of CRA systems. A limitation or problem is a factor that can negatively influence research, creating obstacles for authors. Table 8 details the problems and limitations found in the selected research papers. It is concluded that, nevertheless, these limitations or problems do not significantly affect the implementation of CRA systems.
| Reference | Model | Comment |
| [ |
Comprehensive model for credit scoring | The objective of this model is to support decision-making by collecting data and applying statistics, artificial intelligence, and other techniques. |
| [ |
Economic order quantity model under two-level partial trade credit | This article proposed a two-level credit model for time varying deteriorating items. Due to the granting credit terms, we applied default risk. Moreover, we assume that the supplier/retailer offers the partial trade credit to the retailer/customer. |
| [ |
Optimal backward elimination model and forward regression method | The purpose of this paper is to verify whether there is a relationship between credit risk, main threat to the banks, and the demographic, marital, cultural, and socio-economic characteristics of a sample of 40 credit applicants, by using the optimal backward elimination model and the forward regression method. |
| [ |
Credit evaluation adjustment method | According to the measurement requirement of counterparty credit risk in Basel Accord, counterparty credit risk-weighted asset is the summation of the default risk-weighted asset of counterparty credit risk and the credit valuation adjustment risk-weighted asset. |
| [ |
Additive generalized models | It outlines the implementation via frequentist and Bayesian MCMC methods. We apply them to a large portfolio of credit card accounts, and show how GAMs can be used to improve not only the application, behavioral and macro-economic components of survival models for credit risk data at individual account level, but also the accuracy of predictions. |
| [ |
Logistic regression model | According to the definition of whether the dependent variable borrower defaults in Logistic regression, the borrower is divided into default and non-default. Among them, non-default borrowers are marked as 0, and default borrowers are marked as 1. |
| [ |
Binary spatial regression model | This study applied a binary spatial regression model to measure contagion effects in credit risk arising from bank failures. To derive interconnectedness measures, we use the World Input-Output Trade (WIOT) statistics between economic sectors. |
| [ |
B2B supply chain | Based on the B2B e-commerce platform, it is used for online transactions and transactions between companies and companies. Information, integrating logistics, business flow, information flow, and capital flow for data analysis and processing. |
| [ |
Type-1 OWA Unbalanced Fuzzy Linguistic Aggregation Methodology | The T1OWA operator methodology is used to assess the creditworthiness of European bonds based on real credit risk ratings of individual Eurozone member states modeled as unbalanced fuzzy linguistic labels. |
| [ |
Moral hazard model | Moral hazard is a problem mainly caused by ex-post information asymmetry in a contract especially after signing the contract. This problem arises due to the inability of agents to be able to observe the actions of other agents. |
Three limitations were found in this SLR. First, the fact that logistic regression is the standard approach in the sector (due to explainability regulations) means that there should be a balance between innovation and transparency in credit decision-making. Second, the “No Free Lunch” theorem indicates that algorithms should be adapted to variations in credit data, acknowledging that there is no “one-size-fits-all” approach. Third, default prediction performance in imbalanced classification situations shows that we should not only focus on absolute high accuracy, but on achieving good global performance and generalization ability.
The limitations identified here do not significantly hinder the implementation of CRA systems. However, these challenges should be strategically addressed to further improve the quality and efficiency of CRA in a constantly evolving environment.
This review found CRA solutions in 31 of the selected documents. AI-based algorithms and techniques are present in most of the implementations reported in the articles. Another widely used solution is Neural Networks. Many authors claim that the latter can process data efficiently, be adapted, and combined with other algorithms to improve their performance. Recently, decision trees have become more popular due to their predictive power based on features. Although these solutions have produced good results in implementations of CRA systems, many of them have been validated and tested using simulated databases based on information collected by several banks around the world. These simulated databases can be used to demonstrate the functionality of the systems, but their results do not represent the reality of some organizations.
Among the 31 articles that described solutions for CRA, 16 of them (i.e., 52 % in this sample) reported accuracies above 90 %. Therefore, their solutions were classified as “Very efficient.” In particular, AI techniques showed great efficiency. Although these studies stress the high performance of their systems, some of them may be biased as they reported 100 % accuracies, which is very unlikely.
CRA systems need to have models that determine the variables to be assessed. However, only a few studies analyzed in this review describe the logic behind their solutions for CRA.
Finally, only three articles in this review described the limitations or problems that should be considered in the implementation of their CRA solutions.
4. CONCLUSIONS
Currently, CRA systems are developed all over the world, mainly in China, India, and the US. These countries are particularly interested in constantly innovating in the implementation of CRA systems.
The methods, models, and algorithms reviewed here make a great contribution to these systems. However, their functionality should be analyzed using real (not simulated) databases to ensure that the results represent the reality of many organizations. Among these methods, models, and algorithms, AI was employed in most studies. In particular. Neural Networks and Random Forest were present in most articles. They have been combined with different algorithms to guarantee specific results according to the implementation.
All the solutions analyzed here have shown outstanding efficiency, with their own particularities. Neural Networks—in particular, deep and convolutional Neural Networks—have demonstrated high efficiency due to their ability to predict outcomes based on feature recognition. Their accuracy in the implemented systems is above average. These networks can identify and thoroughly analyze features and patterns in data, which results in accurate, reliable predictions. Likewise, Random Forest-based algorithms exhibited an outstanding predictive power in CRA. These algorithms exploit the diversity and predictive power of a collection of individual trees to offer reliable and consistent predictions, which results in more robust and generalizable models. Nevertheless, this can mean a possible deficiency in cases of large volumes of data or variables, which can increase the computational complexity and require significant processing and storage resources. Although these technologies presented remarkable efficiency, most of the other solutions achieved satisfactory results as well. Still, as some studies referred to margins of error, the methods they employed should be continuously improved and refined.
To develop CRA systems, it is important to describe the logic behind the variables that are involved in the implementation. This logic is not described in many of the articles reviewed here. Therefore, future studies should focus on this specific area to further improve CRA systems. Also, they could examine aspects such as the optimization of AI algorithms more thoroughly to achieve ever greater accuracy in CRA. They should use real data (instead of simulations) to identify and address possible challenges and limitations in the practical implementation of CRA systems. Furthermore, they can include demographic factors in CRA, which is a key opportunity. They can explore how to effectively incorporate these factors and how to adapt models to different populations. Finally, they should investigate the impact that current and future research in this field can have on the financial sector and decision-making regarding credit risk. These studies should benefit financial institutions and consumers in general.
5. ACKNOWLEDGMENTS AND FUNDING
This study did not receive funding from any public or private institution or organization.
CONFLICTS OF INTEREST
The authors declare no conflict of interest.
AUTHOR CONTRIBUTIONS
Frank Edward Tadeo Espinoza drafted the manuscript, developed the methodology, reported the results, and drew the conclusions. Marco Antonio Coral Ygnacio drafted and structured the manuscript.
6. REFERENCES
- arrow_upward [1] S. R. Lenka, S. K. Bisoy, R. Priyadarshini, J. Hota, and R. K. Barik, “An effective credit scoring model implementation by optimal feature selection scheme,” 2021 Int. Conf. Emerg. Smart Comput. Informatics (ESCI), Pune, India, 2021, pp. 106–109. https://doi.org/10.1109/ESCI50559.2021.9396911
- arrow_upward [2] H. Kvamme, N. Sellereite, K. Aas, and S. Sjursen, “Predicting mortgage default using convolutional neural networks,” Expert Syst. Appl., vol. 102, pp. 207–217, Jul. 2018. https://doi.org/10.1016/j.eswa.2018.02.029
- arrow_upward [3] S. Wen, B. Zeng, W. Liao, P. Wei, and Z. Pan, “Research and Design of Credit Risk Assessment System Based on Big Data and Machine Learning,” 2021 IEEE 6th Int. Conf. Big Data Analytics (ICBDA), Xiamen, China,2021, pp. 9–13. https://doi.org/10.1109/ICBDA51983.2021.9403128
- arrow_upward [4] F. Wu, X. Su, Y. S. Ock, and Z. Wang, “Personal credit risk evaluation model of P2P online lending based on AHP,” Symmetry, vol. 13, no. 1, p. 83, Jan. 2021. https://doi.org/10.3390/sym13010083
- arrow_upward [5] J. Nourmohammadi-Khiarak, M.-R. Feizi-Derakhshi, F. Razeghi, S. Mazaheri, Y. Zamani-Harghalani, and R. Moosavi-Tayebi, “New hybrid method for feature selection and classification using meta-heuristic algorithm in credit risk assessment,” Iran J. Comput. Sci., vol. 3, pp. 1–11, Jun. 2020. https://doi.org/10.1007/s42044-019-00038-x
- arrow_upward [6] M. Wang and H. Ku, “Utilizing historical data for corporate credit rating assessment,” Expert Syst. Appl., vol. 165, p. 113925, Mar. 2021. https://doi.org/10.1016/j.eswa.2020.113925
- arrow_upward [7] S. Moradi and F. Mokhatab Rafiei, “A dynamic credit risk assessment model with data mining techniques: evidence from Iranian banks,” Financ. Innov., vol. 5, no. 15, Mar. 2019. https://doi.org/10.1186/s40854-019-0121-9
- arrow_upward [8] A. Fenerich et al., “Use of machine learning techniques in bank credit risk analysis,” Revista Internacional de Métodos Numéricos para Cálculo y Diseño en Ingeniería, vol. 36, no. 3, p. 40, Sep. 2020. https://doi.org/10.23967/J.RIMNI.2020.08.003
- arrow_upward [9] A. Wójcicka-Wójtowicz, A. Lyczkowska-Hanckowiak, and K. Maciej Piasecki, “Credit Risk Assessment by Ordered Fuzzy Numbers,” SSRN Electron. J., Nov. 2019. https://doi.org/10.2139/ssrn.3479218
- arrow_upward [10] A. Niu, B. Cai, and S. Cai, “Big Data Analytics for Complex Credit Risk Assessment of Network Lending Based on SMOTE Algorithm,” Complexity, vol. 2020, p. 8563030, Sep. 2020. https://doi.org/10.1155/2020/8563030
- arrow_upward [11] A. Agosto, P. Giudici, and T. Leach, “Spatial Regression Models to Improve P2P Credit Risk Management,” Front. Artif. Intell., vol. 2, May. 2019. https://doi.org/10.3389/frai.2019.00006
- arrow_upward [12] Y. Cao, “Internet financial supervision based on machine learning and improved neural network,” J. Intell. Fuzzy Syst., vol. 40, no. 4, pp. 7297–7308, Apr. 2021. https://doi.org/10.3233/JIFS-189555
- arrow_upward [13] C. Luo, “A comprehensive decision support approach for credit scoring,” Ind. Manag. Data Syst., vol. 120, no. 2, pp. 280–290, Oct. 2019. https://doi.org/10.1108/IMDS-03-2019-0182
- arrow_upward [14] A. A. Turjo, Y. Rahman, S. M. M. Karim, T. H. Biswas, I. Dewan, and M. I. Hossain, “CRAM: A Credit Risk Assessment Model by Analyzing Different Machine Learning Algorithms,” 4th International Conference on Information and Communications Technology, Yogyakarta, Indonesia, 2021pp. 125–130. https://doi.org/10.1109/ICOIACT53268.2021.9563995
- arrow_upward [15] A. Wójcicka-Wójtowicz and K. Piasecki, “Application of the oriented fuzzy numbers in credit risk assessment,” Mathematics, vol. 9, no. 5, p. 535, Mar. 2021. https://doi.org/10.3390/math9050535
- arrow_upward [16] C. Yung-Chia, C. Kuei-Hu, and H. Yi-Hsuan, “A novel fuzzy credit risk assessment decision support system based on the python web framework,” J. Ind. Prod. Eng., vol. 37, no. 5, pp. 229–244, Jun. 2020. https://doi.org/10.1080/21681015.2020.1772385
- arrow_upward [17] S. Haloui and A. El Moudden, “An optimal prediction model’s credit risk: The implementation of the backward elimination and forward regression method,” International Journal of Advanced Computer Science and Applications, vol. 11, no. 2, p. 9549868, 2020. https://doi.org/10.14569/ijacsa.2020.0110259
- arrow_upward [18] H. Xie and Y. Shi, “A Big Data Technique for Internet Financial Risk Control,” Mob. Inf. Syst., vol. 2022, Jul. 2022. https://doi.org/10.1155/2022/9549868
- arrow_upward [19] L. Cheng-yong, D. Tian-yu, and M. Ling-xing, “The Prevention of Financial Legal Risks of B2B E-commerce Supply Chain,” Wirel. Commun. Mob. Comput., vol. 2022, p. 6154011, Jan. 2022. https://doi.org/10.1155/2022/6154011
- arrow_upward [20] Y. Li, “Credit risk prediction based on machine learning methods,” 14th Int. Conf. Comput. Sci. Education. Toronto, Canada, 2019 pp. 1011–1013. https://doi.org/10.1109/ICCSE.2019.8845444
- arrow_upward [21] A. Liberati et al., The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration, Journal of Clinical Epidemiology, vol. 62, no. 10, pp. e1-e34 Oct. 2009. https://doi.org/10.1016/j.jclinepi.2009.06.006
- arrow_upward [22] Y. Zhu, L. Zhou, C. Xie, W. Gang-Jin, and N. Truong. V, “Forecasting SMEs’ credit risk in supply chain finance with an enhanced hybrid ensemble machine learning approach,” Int. J. Prod. Econ., vol. 211, pp. 22–33, May. 2019. https://doi.org/10.1016/j.ijpe.2019.01.032
- arrow_upward [23] P. Pławiak, M. Abdar, and U. R. Acharya, “Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring,” Appl. Soft Comput. J., vol. 84, p. 105740, Nov. 2019. https://doi.org/10.1016/j.asoc.2019.105740
- arrow_upward [24] X. Huang, X. Liu, and Y. Ren, “Enterprise credit risk evaluation based on neural network algorithm,” Cogn. Syst. Res., vol. 52, pp. 317–324, Dec. 2018. https://doi.org/10.1016/j.cogsys.2018.07.023
- arrow_upward [25] X. Ye, D. Lu-an, and D. Ma, “Loan evaluation in P2P lending based on Random Forest optimized by genetic algorithm with profit score,” Electron. Commer. Res. Appl., vol. 32, pp. 23–36, Nov-Dec. 2018. https://doi.org/10.1016/j.elerap.2018.10.004
- arrow_upward [26] K. Cheng et al., “SecureBoost: A Lossless Federated Learning Framework,” IEEE Intell. Syst., vol. 36, no. 6, pp. 87–98, Nov.-Dec. 2021. https://doi.org/10.1109/MIS.2021.3082561
- arrow_upward [27] K. Masmoudi, L. Abid, and A. Masmoudi, “Credit risk modeling using Bayesian network with a latent variable,” Expert Syst. Appl., vol. 127, pp. 157–166, Aug. 2019. https://doi.org/10.1016/j.eswa.2019.03.014
- arrow_upward [28] Y. Song, Y. Wang, X. Ye, D. Wang, Y. Yin, and Y. Wang, “Multi-view ensemble learning based on distance-to-model and adaptive clustering for imbalanced credit risk assessment in P2P lending,” Inf. Sci., vol. 525, pp. 182–204, Jul. 2020. https://doi.org/10.1016/j.ins.2020.03.027
- arrow_upward [29] D. Liang, T. Chih-Fong, D. An-Jie, and W. Eberle, “A novel classifier ensemble approach for financial distress prediction,” Knowl. Inf. Syst., vol. 54, pp. 437–462, May. 2018. https:/doi.org/10.1007/s10115-017-1061-1
- arrow_upward [30] Y. O. Serrano-Silva, Y. Villuendas-Rey, and C. Yáñez-Márquez, “Automatic feature weighting for improving financial Decision Support Systems,” Decis. Support Syst., vol. 107, pp. 78–87, Mar. 2018. https://doi.org/10.1016/j.dss.2018.01.005
- arrow_upward [31] G. De Tre, A. Hallez, and A. Bronselaer, “Performance optimization of object comparison,” Int. J. Intell. Syst., vol. 24, no. 10, pp. 1057–1076, Jul. 2009. https://doi.org/10.1002/int.20373
- arrow_upward [32] P. Mahata, G. Chandra. Mahata, and S. Kumar. De, “An economic order quantity model under two-level partial trade credit for time varying deteriorating items,” Int. J. Syst. Sci. Oper. Logist., vol. 7, no. 1, pp. 1–17, May. 2020. https://doi.org/10.1080/23302674.2018.1473526
- arrow_upward [33] Y. Li-Li, Q. Yi-Wen, H. Yuan, and R. Zhao-Jun, “A Convolutional Neural Network-Based Model for Supply Chain Financial Risk Early Warning,” Comput. Intell. Neurosci., vol. 2022, p. 7825597, Apr. 2022. https://doi.org/10.1155/2022/7825597
- arrow_upward [34] W. Cheng-Feng, H. Shian-Chang, C. Chei-Chang, and W. Yu-Min, “A predictive intelligence system of credit scoring based on deep multiple kernel learning,” Appl. Soft Comput., vol. 111, p. 107668, Nov. 2021. https://doi.org/10.1016/j.asoc.2021.107668
- arrow_upward [35] W. Yang and L. Gao, “A Study on RB-XGBoost Algorithm-Based e-Commerce Credit Risk Assessment Model,” J. Sensors, vol. 2021, p. 7066304, Oct. 2021. https://doi.org/10.1155/2021/7066304
- arrow_upward [36] S. Lahmiri, A. Giakoumelou, and S. Bekiros, “An adaptive sequential-filtering learning system for credit risk modeling,” Soft Comput., vol. 25, no. 13, pp. 8817–8824, May. 2021. https://doi.org/10.1007/s00500-021-05833-y
- arrow_upward [37] X. Ye, L. an Dong, and D. Ma, “Loan evaluation in P2P lending based on Random Forest optimized by genetic algorithm with profit score,” Electron. Commer. Res. Appl., vol. , pp. 23–36, Nov-Dec. 2018. https://doi.org/10.1016/j.elerap.2018.10.004
- arrow_upward [38] S. Luo, M. Xing, and J. Zhao, “Construction of Artificial Intelligence Application Model for Supply Chain Financial Risk Assessment,” Sci. Program., vol. 2022, p. 4194576, Jun. 2022. https://doi.org/10.1155/2022/4194576
- arrow_upward [39] H. Zeng, “Credit Risk Evaluation in Enterprise Financial Management by Using Convolutional Neural Network under the Construction of Smart City,” Secur. Commun. Networks., vol. 2022, p. 8532918, Aug. 2022. https://doi.org/10.1155/2022/8532918
- arrow_upward [40] A. Merćep, L. Mrčela, M. Birov, and Z. Kostanjčar, “Deep neural networks for behavioral credit rating,” Entropy, vol. 23, no. 1, Dec. 2021. https://doi.org/10.3390/e23010027
- arrow_upward [41] G. Yangyudongnanxin, “Financial Credit Risk Control Strategy Based on Weighted Random Forest Algorithm,” Scientific Programming, vol. 2021, p. 6276155, Oct. 2021. https://doi.org/10.1155/2021/6276155
- arrow_upward 42] Y. Xi and Q. Li, “Improved AHP Model and Neural Network for Consumer Finance Credit Risk Assessment,” Advances in Multimedia, vol. 2022, p. 9588486, Jul. 2022. https://doi.org/10.1155/2022/9588486
- arrow_upward [43] J. R. de Castro Vieira, F. Barboza, V. A. Sobreiro, and H. Kimura, “Machine learning models for credit analysis improvements: Predicting low-income families’ default,” Appl. Soft Comput. J., vol. 83, p. 105640, Oct. 2019. https://doi.org/10.1016/j.asoc.2019.105640
- arrow_upward [44] W. Liu, H. Fan, and M. Xia, “Multi-grained and multi-layered gradient boosting decision tree for credit scoring,” Appl. Intell., vol. 52, pp. 5325–5341, Mar. 2022. https://doi.org/10.1007/s10489-021-02715-6
- arrow_upward [45] B. Li, “Online Loan Default Prediction Model Based on Deep Learning Neural Network,” Computational Intelligence and Neuroscience, vol. 2022, p. 4276253, Aug. 2022. https://doi.org/10.1155/2022/4276253
- arrow_upward [46] M. Almutairi, F. Stahl, and M. Bramer, “ReG-Rules: An Explainable Rule-Based Ensemble Learner for Classification,” IEEE Access, vol. 9, pp. 52015–52035, Feb. 2021. https://doi.org/10.1109/ACCESS.2021.3062763
- arrow_upward [47] W. Liu, H. Fan, and M. Xia, “Step-wise multi-grained augmented gradient boosting decision trees for credit scoring,” Eng. Appl. Artif. Intell., vol. 97, p. 104036, Jan. 2021. https://doi.org/10.1016/j.engappai.2020.104036
- arrow_upward [48] M. Yin and G. Li, “Supply Chain Financial Default Risk Early Warning System Based on Particle Swarm Optimization Algorithm,” Mathematical Problems in Engineering, vol. 2022, p. 7255967, 2022. https://doi.org/10.1155/2022/7255967
- arrow_upward [49] Z. Hassani, M. Alambardar Meybodi, and V. Hajihashemi, “Credit Risk Assessment Using Learning Algorithms for Feature Selection,” Fuzzy Inf. Eng., vol. 12, no. 4, pp. 529–544, Jun. 2020. https://doi.org/10.1080/16168658.2021.1925021
- arrow_upward [50] L. Wang and H. Song, “E-Commerce Credit Risk Assessment Based on Fuzzy Neural Network,” Computational Intelligence and Neuroscience, vol. 2022, p. 3088915, Jan. 2022. https://doi.org/10.1155/2022/3088915
- arrow_upward [51] N. H. Putri, M. Fatekurohman, and I. M. Tirta, “Credit risk analysis using support vector machines algorithm,” J. Phys. Conf. Ser., vol. 1836, p. 012039, 2021. https://doi.org/10.1088/1742-6596/1836/1/012039
- arrow_upward [52] S. Barua, D. Gavandi, P. Sangle, L. Shinde, and J. Ramteke, “Swindle: Predicting the Probability of Loan Defaults using CatBoost Algorithm,” 5th Int. Conf. Comput. Methodol. Commun., Erode, India, 2021, pp. 1710–1715. https://doi.org/10.1109/ICCMC51019.2021.9418277
- arrow_upward [53] Y. Liu and L. Huang, “Supply chain finance credit risk assessment using support vector machine–based ensemble improved with noise elimination,” International Journal of Distributed Sensor Networks, vol. 16, no. 1, Feb. 2020. https://doi.org/10.1177/1550147720903631
- arrow_upward [54] A. L. Leal Fica, M. A. Aranguiz Casanova Y J. Gallegos Mardones. "Análisis De Riesgo Crediticio, Propuesta Del Modelo Credit Scoring". Redalyc, vol. 26, no. 1, pp.181-207, 2018. https://doi.org/10.18359/rfce.2666
- arrow_upward [55] Q. Liu, C. Wu, and L. Lou, “Evaluation research on commercial bank counterparty credit risk management based on new intuitionistic fuzzy method,” Soft Comput., vol. 22, pp. 5363–5375, Feb. 2018. https://doi.org/10.1007/s00500-018-3042-z
- arrow_upward [56] V. B. Djeundje and J. Crook, “Identifying hidden patterns in credit risk survival data using Generalised Additive Models,” Eur. J. Oper. Res., vol. 277, no. 1, pp. 366–376, Aug. 2019. https://doi.org/10.1016/j.ejor.2019.02.006
- arrow_upward [57] D. Mhlanga, “Financial inclusion in emerging economies: The application of machine learning and artificial intelligence in credit Risk assessment,” Int. J. Financ. Studies., vol. 9, no. 3, Jul. 2021. https://doi.org/10.3390/ijfs9030039
- arrow_upward [58] A. Dattachaudhuri, S. K. Biswas, S. Sarkar, A. N. Boruah, M. Chakraborty, and B. Purkayastha, “Transparent Neural based Expert System for Credit Risk (TNESCR): An Automated Credit Risk Evaluation System,” 2020 Int. Conf. Comput. Perform. Eval. ComPE, Shillong, India, 2020, pp. 013–017. https://doi.org/10.1109/ComPE49325.2020.9199998
- arrow_upward [59] P. Z. Lappas and A. N. Yannacopoulos, “A machine learning approach combining expert knowledge with genetic algorithms in feature selection for credit risk assessment,” Applied Soft Computing,vol. 107, p. 107391, Aug. 2021.https://doi.org/10.1016/j.asoc.2021.107391

